Dr. Stuster defends NHTSA validation
theory
From his email, here are SFST validation scientist Dr. Stuster's
corrections of my analysis of SFST validation theory's two great
flaws, "using SFSTs"
and accuracy. I respectfully
decline his corrections.
|
 1
"Using SFSTs" 1
"Using SFSTs"
Dr Stuster writes:
| [Quoting Greg's lies at
FieldSobrietyTest.info]
According to the NHTSA, officers using standardized FSTs still
arrest 29% of the innocent drivers they assess
[Dr. Stuster responds]
Only three drivers were arrested during the study who had BACs
below 0.08: one was under the influence of drugs (BAC=0.0), one
was too impaired to drive at 0.07, and one was 18 years old with
a BAC of 0.07 (in a zero-tolerance state). Not a single
“innocent driver” was arrested. How can you
claim otherwise?
|
Greg replies
This is going to come down to the failure of SFST validation
theory to settle on a single meaning of "using." First,
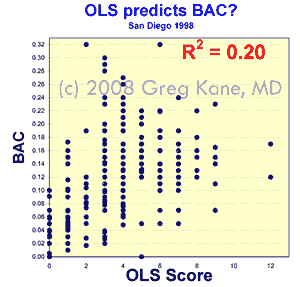
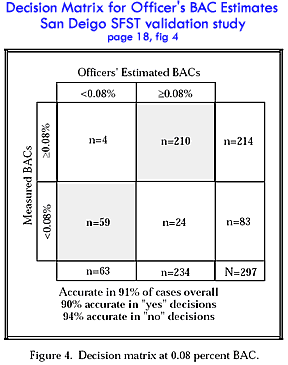
the facts. Here are two versions of the contingency
table tallying the findings of the San Diego study regarding
officer BAC estimates compared with actual BAC levels.
|
NHTSA's
official report
|
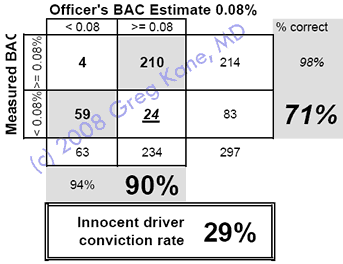
Greg's
version
Same data, more calculations
|
 |
|
The NHTSA's official report gives prevalence
dependent accuracies only. These accuracies do not apply
to drivers not in this study group.
The NHTSA's official report fails to disclose
the scientifically
standard, prevalence independent, statistics specificity
and sensitivity. Thus the study avoids letting on that
the accuracy of officer BAC estimates on innocent people is
only 71%
|
Greg's version of this same data adds two
standard scientific calculations:
impaired driver accuracy (sensitivity) = 98%
innocent driver accuracy (specificity) = 71%.
These accuracies are not prevalence-dependant, so they apply
to drivers not in the study. Which is why established scientific
journals require them...


|
The point Dr Stuster disputes is that if
officer arrests are guided by officer BAC estimates (which we
are told to believe are arrived at by "using SFSTs")
then officers will arrest 29% of the innocent people they assess.
To the extent officers do not arrest drivers who fail the SFST,
officers are not using the SFST.
But, says Dr. Stuster, officers didn't
arrest all those innocent people. Innocent driver  arrest
wise, officers "using SFSTs" were perfect. arrest
wise, officers "using SFSTs" were perfect.
What Dr. Stuster fails to say is officers weren't using just
SFSTs. They were also using
portable breath testing machines! Officers stopped
drivers, did SFSTs, estimated BACs, then did a portable breath
test for actual alcohol level.
Dr. Stuster asks us to believe SFSTs are accurate because officers
"using SFSTs" estimated drivers to have high alcohol
levels, then did a breathalyzer that proved otherwise, after
which the innocent drivers were released. What crime officers
might arrest just-proven-innocent people for, Dr. Stuster doesn't
say.
Good. We've clarified the facts and identified the thing
Dr. Stuster and I disagree about. Dr. Stuster's meaning
of "using SFSTs" includes officers doing SFSTs,
but basing their decisions on a breathayzer. I think what Dr.
Stuster has in mind is better said, "doing SFSTs, but using
a breathalyzer (or other non-SFST facts)" In my opinion,
"using SFSTs" should mean "were guided by SFST
results" -- that officer results and SFST results matched.
Either definition works, as long as you're consistent. The trouble
with NHTSA SFST validation theory is, it fails to be consistent
about this definition. More
on this in a minute.
Now we know Greg's original point
underestimated the SFST failure rate
The point Dr. Stuster imagines himself correcting
was written before I had access to the San Diego validation study's
data. Now that data is available, the point can be strengthened.
If officers "using SFSTs" rely on those SFSTs to make
their arrest decisions, they will wrongly arrest not
29% but 71% of the innocent people they assess.
|
| Original
claim
based on data in the SFST validation study report
revealing officer BAC estimates but not SFST results
|
Updated claim
based on raw SFST study data using standardized SFST interpretation
criteria for BAC 0.08%
|
|
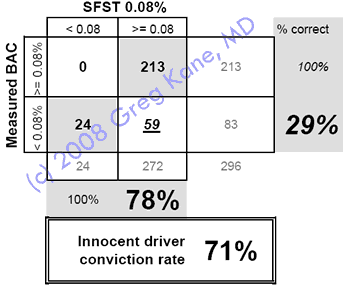 |
83 innocent people
were assessed by officers
Officers estimated 24 of those 83 innocent people
had high BACs—29%
|
83 innocent
people took the SFST
The SFST indicated that 59 of those 83 innocent
people had high BACs —71% |
| |
Updated claim
based on raw study data
using standardized SFST interpretation criteria for BAC
0.04% |
|
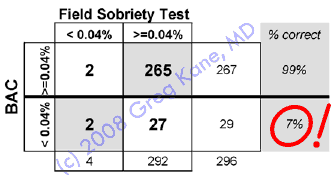
And if officers target a lower BAC with the more
stringent standardized SFST interpretation criteria imagined to
identify BACs of 0.04%, then officers will wrongly arrest 93%
of the innocent drivers they assess.
Here are the facts >>
|
 |
| |
29 innocent
people took the SFST
The SFST indicated that 27 of those 29 innocent people had high
BACs—93% |
To the extent officers do not arrest people the SFST instructs
them to arrest, officers are not "using SFSTs."
This is more than a pedantic quibble, because...
Imprecision
about what "using SFSTs" means
is a deep and fundamental flaw in SFST validation theory.
Lets talk about that some more...
|
SFST validation theory defines "using SFSTs"
two different ways.
|
|
SFST validation theory
in court
& Greg |
 In
court study officers "using SFSTs" is taken to mean
"were guided by SFST results," as if
study officers' decisions had matched SFST results. If test results
and officer results had matched, SFST accuracy and officer accuracy
would also match. In
court study officers "using SFSTs" is taken to mean
"were guided by SFST results," as if
study officers' decisions had matched SFST results. If test results
and officer results had matched, SFST accuracy and officer accuracy
would also match.
This version of "using" is critical to SFST
validation theory. If true, it would mean that in any
DUI prosecution having the SFST result would allow the prosecution
to reproduce the high (albeit misleading)
accuracy of officers in the validation study. But it is not
true. |
|
SFST validation theory
in validation studies
& Dr. Stuster |
 In
validation studies' official reports, "using SFSTs"
means something else. Now it means nothing more than "doing
SFSTs." Including, "Doing SFSTs, but ignoring
the results." Officers did SFSTs, but they were
free to accept or reject the results. Very often what officers
did was reject them. In
validation studies' official reports, "using SFSTs"
means something else. Now it means nothing more than "doing
SFSTs." Including, "Doing SFSTs, but ignoring
the results." Officers did SFSTs, but they were
free to accept or reject the results. Very often what officers
did was reject them.
How do validation studies track SFST rejections? They don't.
Any officer who did an SFST was counted as using
the SFST. I am not making this up. Every time officers estimated
BAC in accordance with standardized SFST interpretation criteria,
they were reported as "using SFSTs." And every time
officers violated clear and explicit SFST interpretation criteria,
they were still reported as "using SFSTs"!
In making their BAC estimates officers rejected false
positive SFST results
59% of the time—and every one of those SFST rejections
was reported as an officer "using SFSTs."
And, as Dr. Stuster points out, in making their arrest decisions
officers with breathalyzer results in hand rejected
false positive SFST results 100% of the time—and
Dr. Stuster's analysis reports every one of those rejections as
an officer "using SFSTs"!
With Dr. Stuster's method—which is the NHTSA's SFST validation
theory's method — SFST validation comes down to Heads
I win, tails you lose. |
Here's
how Greg replied to Dr. Stuster:
Dr. Stuster, let me begin
by explaining my rational. Our scientific disagreement
on this point centers on what is, in my opinion, another of
your scientific errors in this study. You failed to
define and quantify "using." In your study,
officers could, and repeatedly did base their decisions on something
other than your clear and explicit SFST interpretation criteria.
As you write on page 20 of your report:
It is
unknown why the officers did not follow the test interpretation
guidelines in these two cases.... Similarly, in seven of the
false positive cases listed previously in Table 6 officers apparently
did not follow the test interpretation guidelines...
In your analysis of your data you used these results
to tally the accuracy of officers "using" SFSTs. When
officers' decisions were guided by the SFST, you counted them
as "using" the SFST. When officer decisions
clearly and repeatedly violated standardized SFST criteria,
you still counted them as "using" the SFST.
You apparently chose not to investigate how often
this happened. I did. In examining your data I discovered, as
I have mentioned, that officers based their decision on something
other than your standardized interpretation criteria fully
59% of the time—when the SFST error would have
lead to a mistaken arrest, but only 2% of the time when the
SFST error would have led to a mistaken release. The probability
that this distribution of SFST rejections happened by chance
is tiny. Dr. Stuster, your own study officers systematically
ignored the standardized SFST interpretation criteria.
Further Dr. Stuster, it seems to me that in order
to know which SFST results to ignore and which to accept, officers
must have based their decisions on something other than the
SFST in every case. In short, in my opinion, the science proves
that officers in your study simply did SFSTs, but their decisions
were not guided by the standardized SFST interpretation criteria.
This conclusion is confirmed by the officers'
BAC estimates – to two decimal places. Nothing in the
standardized interpretation criteria allows BAC estimates to
this precision. And yet officers made predictions to this precision,
and you used those predictions to "validate" the SFST.
You did not "validate" the SFST results, you "validated"
the officers BAC estimates. The officers' BAC estimates
were not, and could not have been, derived from the drivers'
SFST results and the standardized SFST interpretation
criteria.
In my opinion, the science is clear. Officers
in your study did SFSTs, they did not use SFSTs. Their decisions
were not controlled by the standardized SFST interpretation
criteria.
Now to your analysis of
this particular claim. First, as you write in your report,
page 10:
All police
officers participating in the study were equipped
with NHTSA approved, portable
breath testing devices to
assess the BACs of all drivers who were administered the SFSTs,
including those who were released without arrest.
Dr. Stuster, if it is your position that the SFST
is valid because officers using breath
testing devices released innocent drivers who failed
the SFST, then we have identified a point at which our opinions
disagree.
You ask, so let me explain
the basis of my claim. Using your data I calculate the
decision matrix for the SFST as
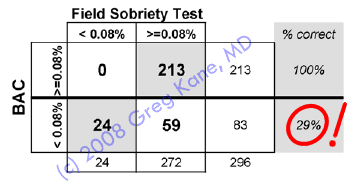
At BAC 0.08% 83 innocent drivers were administered
the SFST. Using the standardized FST interpretation criteria
printed on page 12 of your study, I calculate that 59 of those
drivers failed the SFST and 24 passed.
Dr. Stuster, in reviewing my claims and comparing
them with the evidence, what were the results of your calculations
here? If my calculations are incorrect, please let me know.
As to my claim, our difference seems to come down
to, "using." As far as I can tell in your study you
do not quantify what you mean by "using. If
you do have a specific mathematical definition in mind, please
let me know. Absent a definition from you, I used the one that
seems most reasonable and that, I think, reflects the mistaken
general understanding of your study's results. I intend "using"
to mean "relying on," or "having their decisions
controlled by." In this I am confirmed by:
"IT
IS NECESSARY TO EMPHASIZE THIS VALIDATION APPLIES ONLY WHEN
...THE STANDARDIZED CRITERIA ARE EMPLOYED TO INTERPRET THAT
PERFORMANCE.
IF ANY
ONE OF THE STANDARDIZED FIELD SOBRIETY TEST ELEMENTS IS CHANGED,
THE VALIDITY IS COMPROMISED."
NHTSA DWI Detection and Standardized Field Sobriety Testing,
Student Manual, 2004 Edition, page VIII-19
It seems to me any definition of "using"
other than "having their decisions controlled by"
would violate these published NHTSA guidelines and amount to
not using the SFST. Your data indicates that if officer decisions
are in fact controlled by the SFST, officers will in fact wrongly
arrest 29% of the innocent people they assess. To the
extent your study officers did not arrest these people, they
were violating the standardized SFST interpretation criteria
and not "using" the SFST, in particular not
as prescribed in the NHTSA's DWI detection manual.
Further on this point, would you agree with me
that to the extent study officers violated and ignored
clear and explicit standardized SFST interpretation criteria,
the study fails to validate the standardized SFST interpretation
criteria, but in fact validates the officers' unstandardized
gut instinct?
If this is not true, it seems you must be saying,
"If officers' decisions were controlled by the SFST interpretation
criteria, the SFST is valid. And if officers' decisions were
controlled by something else, in direct contradiction to the
SFST result, the SFST is still valid." In which case, SFST
validation comes down to Heads I win, tails
you lose.
Dr. Stuster, if this analysis is mistaken, please
show me how. I am anxious to make FieldSobreityTest.info as
accurate as possible.
|
2
Skewed sample, skewed accuracy
Dr Stuster writes:
[Quoting Greg's lies at
FieldSobrietyTest.info]
Simply by adjusting the balance of impaired and sober drivers
in the study group, NHTSA contractors can dial in the accuracy
their research "discovers." And
Simply by manipulating the group of drivers you choose to “study,”
you can set up your validation study beforehand so
it is certain to “discover” whatever arrest accuracy
you’ve been paid to validate.
[Dr. Stuster responds]
Neither NHTSA nor I selected the drivers who were stopped. Drivers
were stopped during the study period who officers observed exhibiting
a driving error or violation, which is the only legal procedure
that could be followed to assess the SFSTs under field conditions.
Only one case was excluded from analysis and that was because
the driver refused all chemical tests. There was no a
priori selection of subjects and NO manipulation of data,
except by you in your examples.
|
Dr. Stuster imagines himself correcting my analysis of SFST
validation theory's "accuracy" flaw. My analysis is
two fold.
First, it is
generally wrong—unhelpful, uninformative,
irrelevant, misleading—to report diagnostic test accuracies
with just the accuracy statistic. The accuracy statistic NHTSA
validation theory imagines "validates" the SFST in fact
applies only to the group of drivers in the validation study.
In other groups the test will have other accuracies. Accuracies
that swing from zero percent to one-hundred percent, depending
entirely on the the mix of drivers in the test group.
Accuracy explains
why the accuracy statistic works this way. The page gives an example
showing exactly how it works, and cites and quotes
the solution to this group-dependence problem used by, among thousands
of others, the worlds largest medical journal—to be
meaningful, studies must report accuracy using non-group-dependent
statistics. This is as basic as basic science gets.
To this point Dr. Stuster has no defense. He
offers no analysis, no equations, no text to support SFST validation
theory's imagination that the accuracy statistic reported in SFST
validation studies is the number that reflects the probability
that a DUI defendant who failed an SFST did in fact have a high
BAC. He does not because he cannot. It isn't true.
Second,
I observe that NHTSA validation studies skew
their sample populations, their study groups, in a way that inflates
the accuracies they discover. They load up on drunks.
Dr. Stuster does not deny that SFST validation
studies' study groups are skewed toward impairment. He does not
deny that those skewed groups inflate the accuracy the studies
"discover." Let us accept he cannot.
QED. At this point my analysis
is complete. It is is generally wrong—unhelpful,
uninformative, irrelevant, misleading—to interpret diagnostic
test results with just the accuracy statistic. What's more, the
high accuracies "discovered" by NHTSA validation studies
are caused by, would not have happened but for, the skewed samples.
Dr. Stuster writes "There
was no a priori selection of subjects"
Dr. Stuster is mistaken. Before the first officer set
out on his first patrol, the San Diego SFST validation study's
study design assured that the group of people who would be studied
would be skewed toward drunks. The study design excluded drivers
who drove well. The study design excluded people driving during
the day (officers patrolled late at night). The study design excluded
drivers who looked and smelled and acted sober. In fact the study
design deliberately excluded everyone highly
experienced DUI patrol officers thought was sober.
Using those inclusion criteria, and big city late at night patrol
tactics, veteran DUI officers were able to come up with a study
group that was 90% guilty, at 0.04% BAC, before
they began doing SFSTs. And after they did their
SFSTs? After doing SFSTs, they ended up with a group of drivers
that was 91% guilty. The SFST itself is responsible for 1% of
that 91% accuracy!
Dr. Stuster continues: "There
was... NO manipulation of data, except by you in your
examples."
I never said there was.
| A
personal note
 Since
Dr. Stuster seems to take my scientific criticisms of his
scientific work personally enough to threaten me, here's
a personal note. I came away from my first exchange with
Dr. Stuster, the one where he quickly and kindly sent me
the study's data, feeling he is an honest, earnest FST
believer. Wrong, but honestly so. He was cheerful and friendly.
Nice. I still believe that. Since
Dr. Stuster seems to take my scientific criticisms of his
scientific work personally enough to threaten me, here's
a personal note. I came away from my first exchange with
Dr. Stuster, the one where he quickly and kindly sent me
the study's data, feeling he is an honest, earnest FST
believer. Wrong, but honestly so. He was cheerful and friendly.
Nice. I still believe that.
On account of which, I feel
particularly bad about attacking the science in Dr. Stuster's
scientific paper. I suspect my scientific criticisms of
his scientific method are new and surprising to him. It
is only natural that he takes them to be personally hurtful.
I understand the impulse to lash out. Unfortunately I must
balance my professional unkindness to him against the harm
done by what I understand to be faulty sobriety tests.
|
|
Here's
how Greg replied to Dr. Stuster:
| First
Dr. Stuster, this claim does not name you. It does not say that
you or anyone else did anything. It merely states a scientific
fact: it is possible to change the accuracy a test discovers by
changing the group studied. To identify a scientific error,
I must first describe what the error was.
Second, when you
write "Neither NHTSA nor I selected the drivers who were
stopped," you are refuting a point
I do not make. I do not believe and have never written
that you yourself selected individual test subjects, or that you
were in any way dishonest or manipulative of the data.
Let me further explain my scientific opinion of
your scientific methods.
Your error was not in personally selecting the
drivers who were stopped, Your error was in having officers select
only drivers who were stopped, and worse than that only
drivers who showed signs of impairment. In my opinion the way
the math works out, the non-random sampling you designed
into your study directly inflated the "accuracy" you
discovered, compared to the accuracy you would have discovered
if you had chosen subjects at random from the population, or at
random from drivers in general. This is not a claim that you had
knowledge or intention to deceive. It is simply a statement of
basic mathematics.
The standard formula for this
is: 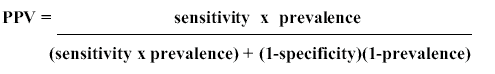
Where PPV is Positive Predictive Value – effectively
the "accuracy" you report. As you will quickly see,
the "accuracy" is a function of prevalence—the
percentage of people in the sample group who have the condition
tested for. Adjusting the prevalence adjusts the "accuracy"
you discover. Again, this is not a claim you had knowledge
or intention to deceive. It is simply a statement of basic mathematics.
My own calculations indicate this study
design error explains all the NHTSA's FST validation
successes. Studies designed with non-random samples leading
to inflated high-BAC prevalences "discover" high accuracies.
Studies with low high-BAC prevalences do not. When the inflated
prevalences are removed, the high "accuracy" disappears.
The amount of knowledge about impairment added by the SFST is
so low as to be not relevant to decisions about guilt.
|
3
Intent to deceive
Dr Stuster writes:
|
[Quoting Greg's lies at
FieldSobrietyTest.info]
If you are being paid to discover an accuracy of 91%, set up a
study group 83% of whose drivers are impaired.
[Dr. Stuster responds]
I was NOT paid to discover that the SFSTs were accurate and I
am offended by your libelous statements. I was paid to conduct
a field study and to analyze and present the results. I have reported
unwelcome results on many occasions when the data do not support
a hypothesis and was under no obligation to perform my work differently
during this study. I am angered by your unfounded accusations
concerning my integrity. |
I don't know if Dr. Stuster is crooked or not. And I don't care. I
care about SFST tests. NHTSA SFST validation theory is not wrong because
NHTSA scientists are corrupt. NHTSA SFST validation theory is wrong
because it ignores basic science.
|
"Authors
are expected to provide detailed information
about all relevant financial interests and relationships
or financial conflicts within the
past 5 years and for the foreseeable future (eg, employment/affiliation,
grants or funding, consultancies, honoraria, stock
ownership or options, expert testimony, royalties,
or patents filed, received, or pending), particularly
those present at the time the research was conducted
and through publication, as well as other financial
interests (such as patent applications in preparation),
that represent potential future financial
gain."
Journal
of the American Medical Association
Instructions For Authors, 2008, pg 2;
also in JAMA, July 2, 2008-Vol 300, No. 1 |
|
|
Here's
how Greg replied to Dr. Stuster:
| Dr. Stuster, the statement
flatly does not refer to you. It explicitly and clearly refers
to a hypothetical person. It clearly does so in order demonstrate
the connection between "accuracy" and studies done on
non-random sample populations.
Is this mathematical statement incorrect? If so how? I am anxious
to correct any mistake I have made.
That said, if you believe some part of this is unclear, let me
know what and how. I will rewrite the section to fix any confusion.
I want FieldSobreityTest.info to be as clear as possible. |
|